The 700ms wall: what callers actually do at each latency band
Everyone benchmarks voice-AI latency. Almost nobody talks about what callers DO at each delay band. Under 500ms feels human; ~700ms reads as robotic; 900ms+ and they talk over the agent or hang up.

Everyone benchmarks voice-AI latency. Almost nobody talks about the thing that actually matters: what callers DO at each delay band.
Latency isn't a number on a slide. It's a behavior trigger. Cross the wrong threshold and the caller stops cooperating with the conversation.
Under 500ms feels human. Around 700ms reads as robotic. Past ~900ms, callers talk over the agent or hang up. Latency is the wall between convert and die.
The three bands
Under 500ms — human
The reply lands in the rhythm a person expects. Callers don't notice the technology; they just have a conversation. This is the band you're aiming for on every turn.
Around 700ms — "robotic"
It still works, but something feels off. The caller can't name it, but they downgrade their trust: they speak more slowly, repeat themselves, start "talking to a machine" instead of talking to an agent. You haven't lost the call — but you've lost the illusion.
900ms and up — they take over
This is the wall. The silence is long enough that the caller assumes it's their turn: they talk over the agent, repeat the question, or hang up. No model quality saves you here — the answer arrives after the caller has already moved.
Why this is a conversion line, not a benchmark
A demo can hide latency. A real call can't. The difference between a 480ms agent and a 720ms agent doesn't show up in a spec sheet — it shows up in completed bookings, in callers who stay on the line, in the share of calls that resolve without a human.
That's why we treat the sub-500ms target as a product requirement, not a brag.
Measure the gap the caller feels
Per-component latency is for tuning. The number that predicts behavior is end-of-speech → first-audio: the moment the caller stops talking to the first sound of the reply. Optimize that, and the bands above take care of themselves. For the engineering picture, see how we get voice AI under 500ms — and for the nuance the infra community pushed back with, latency, corrected: P95, P99, and jitter.
Build an agent that answers in the sub-500ms band. Free to start — $5 in credits, no card.
Frequently asked
Q.What is a good response latency for a voice AI agent?
Aim for under 500ms from end-of-speech to first audio back. At that band the exchange feels human and callers stay in a normal conversational rhythm. Around 700ms it still works but starts to read as 'robotic,' and past about 900ms callers begin to talk over the agent or hang up. Latency isn't a vanity benchmark — it's the line between a call that converts and one that dies.
Q.How do you measure voice agent latency correctly?
Measure the gap the caller actually feels: from the moment they stop speaking (end-of-speech) to the first audio of the agent's reply. That spans speech-to-text finalization, the LLM response, and text-to-speech first byte. Internal per-component numbers matter for tuning, but the end-of-speech-to-first-audio figure is what determines caller behavior.
Q.Why does latency matter more than model quality in voice?
A brilliant answer delivered a beat too late still breaks the conversation — the caller has already filled the silence or disengaged. In voice, timing is part of the answer. Past the ~900ms band, even a perfect response arrives after the caller has talked over it.
Q.How does Call2Me keep latency low?
Call2Me runs a tuned STT-LLM-TTS pipeline with a sub-500ms median end-to-end target, so turn-taking stays in the human band. See our latency deep dive for the engineering detail.
Keep reading
All posts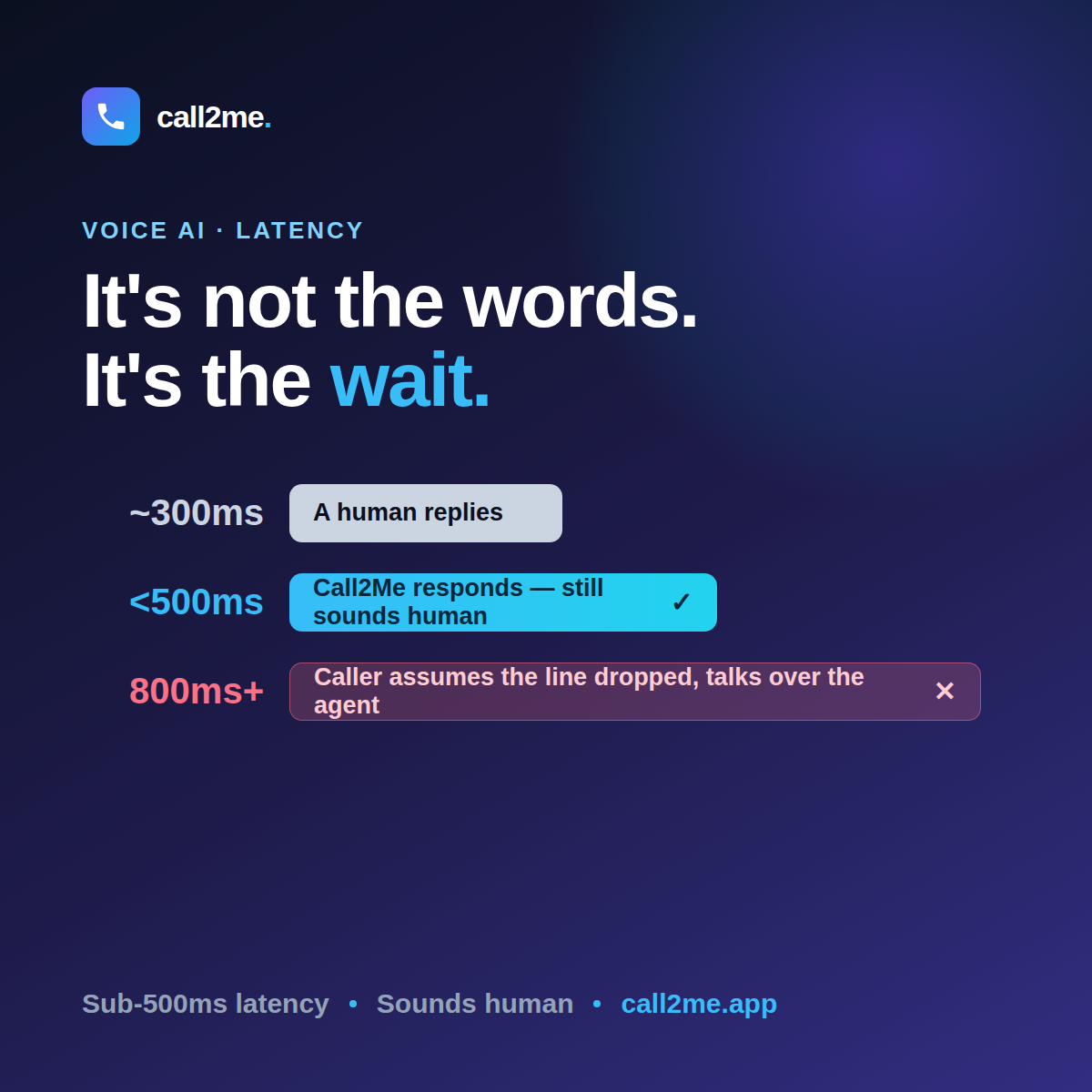 Voice AI
Voice AIThe silence problem: why AI voice demos fail
Most AI voice demos fail on the same thing — and it isn't the words. It's the silence. People answer in about 300ms; past 800ms the caller talks over the agent. Latency is the product.
Jun 12, 20261 min Voice AI
Voice AILatency, corrected: P95, P99, and the jitter you can't beat
A popular post on the 700ms latency wall drew pushback from the voice-infra community. Three corrections worth keeping: it's not 'fast' but 'well-timed'; track P95/P99 not the average; you don't beat the telco leg, you plan around it.
Jun 23, 20262 min Voice AI
Voice AIBarge-in: the feature that separates a demo from a product
You can tell an AI voice agent is fake the moment you try to interrupt it. Real conversation isn't strictly turn-based — people cut in. Barge-in means detecting that in under 300ms, stopping mid-word, and re-planning.
Jun 15, 20262 min