Latency, corrected: P95, P99, and the jitter you can't beat
A popular post on the 700ms latency wall drew pushback from the voice-infra community. Three corrections worth keeping: it's not 'fast' but 'well-timed'; track P95/P99 not the average; you don't beat the telco leg, you plan around it.

A while back we argued that voice-AI latency is a wall: under 500ms feels human, ~700ms reads robotic, 900ms+ and callers take over. It struck a nerve — and the people who build voice infrastructure for a living pushed back with corrections sharper than the original post.
Here are the three worth keeping.
- It's not fast, it's well-timed. 2. The average lies — track P95/P99. 3. You don't beat the telco leg; you plan around it.
1. "Fast" is the wrong target — "well-timed" is
The instinct is to minimize milliseconds on every turn. But a human doesn't answer every question at the same speed. A confident answer comes back quickly; an uncertain one is preceded by a beat of thought. An agent that always fires instantly can feel as unnatural as one that lags. The goal is a rhythm that fits the conversation — fast when the answer is obvious, a natural pause when it isn't.
2. The average is a vanity metric — P95/P99 is the truth
Callers don't experience your median latency. They experience the worst turns. A clean average can hide a tail where one call in twenty stalls long enough to break. That tail — P95, P99 — is what the customer remembers and what your retention reflects. If you only watch the average, you're optimizing the number nobody feels.
3. You can't beat the telephony leg — plan around it
The STT-LLM-TTS pipeline is yours to tune. The telco leg is not. The PSTN/SIP path adds delay and jitter you don't control. Pretending it's zero is how a great demo becomes a shaky production call. The fix isn't to "win" the network — it's to budget for it in your latency target and design turn-taking that tolerates variance.
Why we publish the pushback
Building in public means the comments are often sharper than the post. These three corrections made our own latency targets more honest: optimize the tail, time the turn, and respect the parts of the path you don't own. For the behavioral thresholds behind all of this, see the 700ms wall, and for the pipeline itself, how we get voice AI under 500ms.
Build a voice agent on a pipeline that's measured where it matters. Free to start — $5 in credits, no card.
Frequently asked
Q.Should I track average latency or P95/P99 for a voice agent?
Track P95 and P99, not the average. Callers don't remember your median response — they remember the worst few turns, the ones where the agent lagged and they talked over it. An average can look healthy while the tail (P95/P99) quietly breaks one call in twenty. Optimize the tail and the felt experience follows.
Q.What does 'well-timed, not fast' mean for voice AI?
Raw speed isn't the goal — appropriate timing is. A confident answer should come back fast; an uncertain one is better preceded by a short, natural pause or filler than rushed out wrong. Humans pause when they think; an agent that always fires instantly can feel as off as one that lags. The target is a rhythm that matches the conversation, not the lowest possible millisecond on every turn.
Q.Can you eliminate telephony latency?
No. The PSTN/SIP leg adds jitter and delay you don't control — you can't beat the telco path, you plan around it. That means budgeting for it in your latency target, choosing routes carefully, and designing turn-taking that tolerates variance rather than assuming a perfectly stable round-trip.
Q.Where can I read the original latency argument?
See our post on the 700ms wall — what callers do at each latency band — for the behavioral thresholds these corrections refine.
Keep reading
All posts Voice AI
Voice AIThe 700ms wall: what callers actually do at each latency band
Everyone benchmarks voice-AI latency. Almost nobody talks about what callers DO at each delay band. Under 500ms feels human; ~700ms reads as robotic; 900ms+ and they talk over the agent or hang up.
Jun 19, 20262 min Voice AI
Voice AIAnswering machine detection: the silent killer of outbound AI
About half of outbound calls go to voicemail. If your AI can't tell a human from a machine, it pitches the beep — and burns the lead. Answering machine detection tells them apart in about two seconds.
Jun 17, 20262 min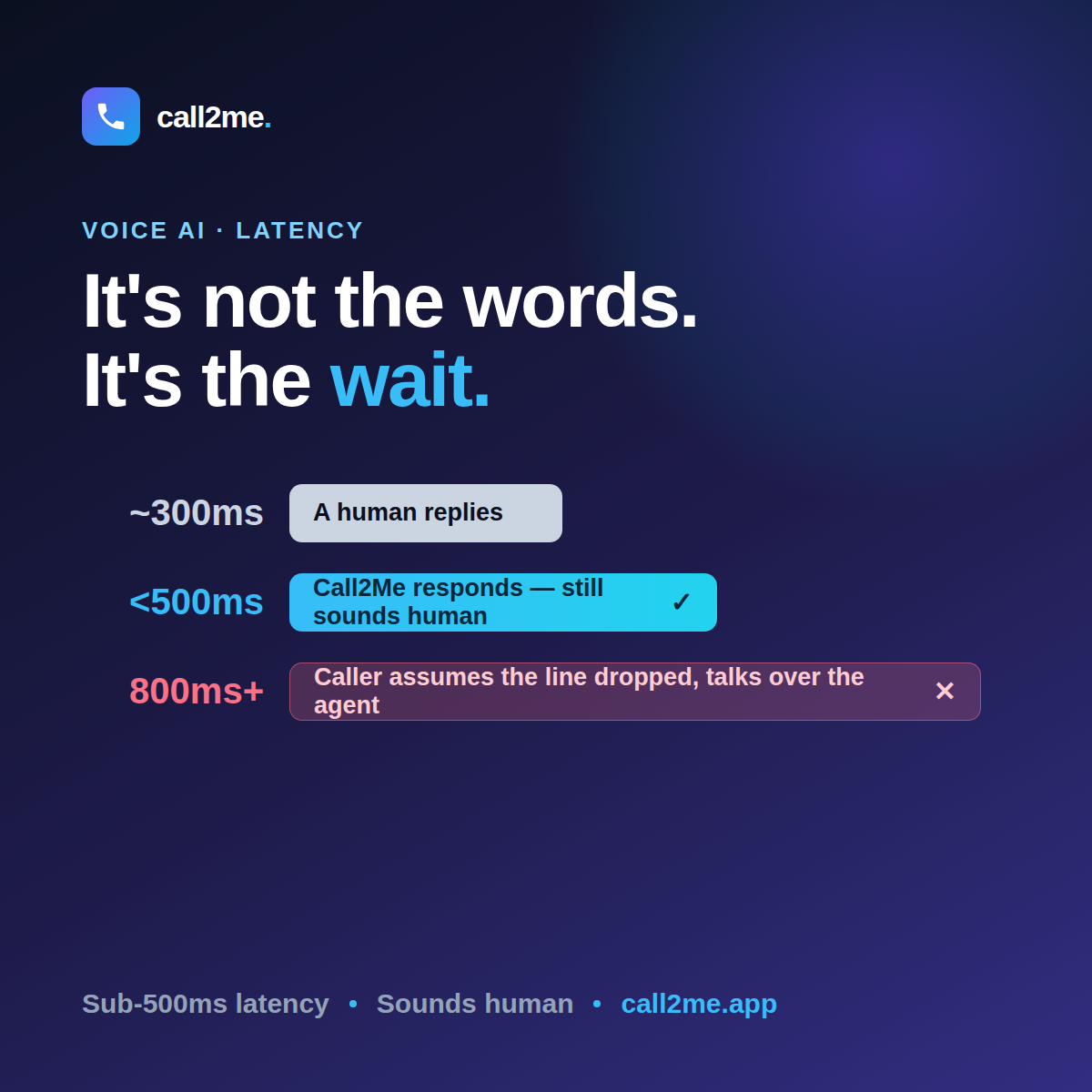 Voice AI
Voice AIThe silence problem: why AI voice demos fail
Most AI voice demos fail on the same thing — and it isn't the words. It's the silence. People answer in about 300ms; past 800ms the caller talks over the agent. Latency is the product.
Jun 12, 20261 min